
Data is the new oil, right? But unlike crude, you don’t need rigs to mine it. You need crawlers or scrapers.
In this review, we’ll look at Scraping Robot — a web scraper tool — we’ll explore how it works and what value you can get from it.
Scraping Robot promises you can save time and pursue meaningful work opportunities because you don't have to spend hours upon hours manually collecting data from social media profiles, e-commerce sources, websites, job boards, and others.
You can use the data you collect to gain clearer insights about your business, do better market research, and get ahead of your competitors who aren't scraping.
What’s web scraping, how does scraping work, and how do you use it ethically?
Let’s explore the answers.
What’s Web Scraping?
When you copy data from a website to a spreadsheet, database, or other central location for later retrieval, you’re scraping the web. But doing it manually can take a lot of time, so we’ve come to trust software solutions to help us get the work done.
You can automate this data collection process using web crawlers. Web scraping is also called web harvesting or web data extraction.
Web scraping can happen with any of these eight techniques:
- Document Object Model (DOM) parsing
- HTML parsing
- Human copy-and-paste
- Vertical aggregation
- Text pattern matching
- Semantic annotation recognizing
- Computer vision web-page analysis
- HTTP programming
We won’t get into the nitty-gritty of each process. Just know you can collect data from websites in more ways than one.
8 Habits of Ethical Web Scrapers
The biggest argument against web scraping is the ethics of it. Just like anything that gives us leverage — money and the internet, for example — bad actors will take advantage of it.
If you use web scraping ethically, it’s a good thing. It comes down to your moral standards.
How do ethical people use web scraping?
1. Honor the Robots Exclusion Standard
Robots Exclusion Standard or the robots.txt file shows a web crawler where it can crawl or not crawl on a website.
It’s the Robots Exclusion Protocol, REP, that regulates how crawlers access a site.
Don’t ignore the rules of the robots.txt file when you crawl a site.
2. Prioritize the Use of an API
If a website has provided an API, so you don’t have to scrape its data, use the API. When you use an API, you’d be following the rules of the site owner.
3. Respect Other People’s Terms and Conditions
If a website has a fair use policy or terms and conditions for accessing their data, respect it. They have been open about what they want, don’t ignore them.
4. Scrape at Off-Peak Hours
Don’t drain a site’s resources by placing requests when it’s busy. Apart from the cost implication, you might be sending a false signal to the site owner that the site is under a DDoS attack.
5. Add a User-Agent String
When scraping a site, consider adding a user-agent string to identify yourself and make it easy for them to contact you. When a site’s admin notices an unusual spike in traffic, they would know for sure what’s happening.
6. Seek Permission First
Seeking permission is a step ahead of the user-agent string. Ask for the data before you even start scrapping it. Let the owner know that you’re going to use a scraper to access their data.
7. Treat the Content with Care and Respect the Data
Be honest with your use of the data. Take only the data you want to use and scrape a site only when you need it. When you’ve accessed the data, do not share it with other people if you don’t have the owner’s permission.
8. Give Credits Where Possible
Support the site by sharing their content on social media, giving them credit when you use their work or doing something to drive human traffic to the site in appreciation.
Starting with Scraping Robot
What should you expect from Scraping Robot?
I’ll take you through this software, step by step.
Naturally, my first step here was to sign up for a free Scraping Robot account. So I clicked on Sign Up to initiate the process.
I filled the form that followed.
It takes me to a dashboard where I can start using the scraper.
Whether you click the blue Create Project button or select Module Library from the side menu, you’ll arrive on the same page.
How Scraping Robot Works
Scraping Robot offers users 5000 scrapes for free every month. That’s enough if the data set you’re looking for is a small one, but if you want more scrapes, then you’re paying $0.0018 per scrape.
Here’s Scraping Robot’s process.
Step #1: Place Your Scraping Request
Choose a module that fits your request, put in your data request. Scraping Robot would then use that information to initiate the scraping process.
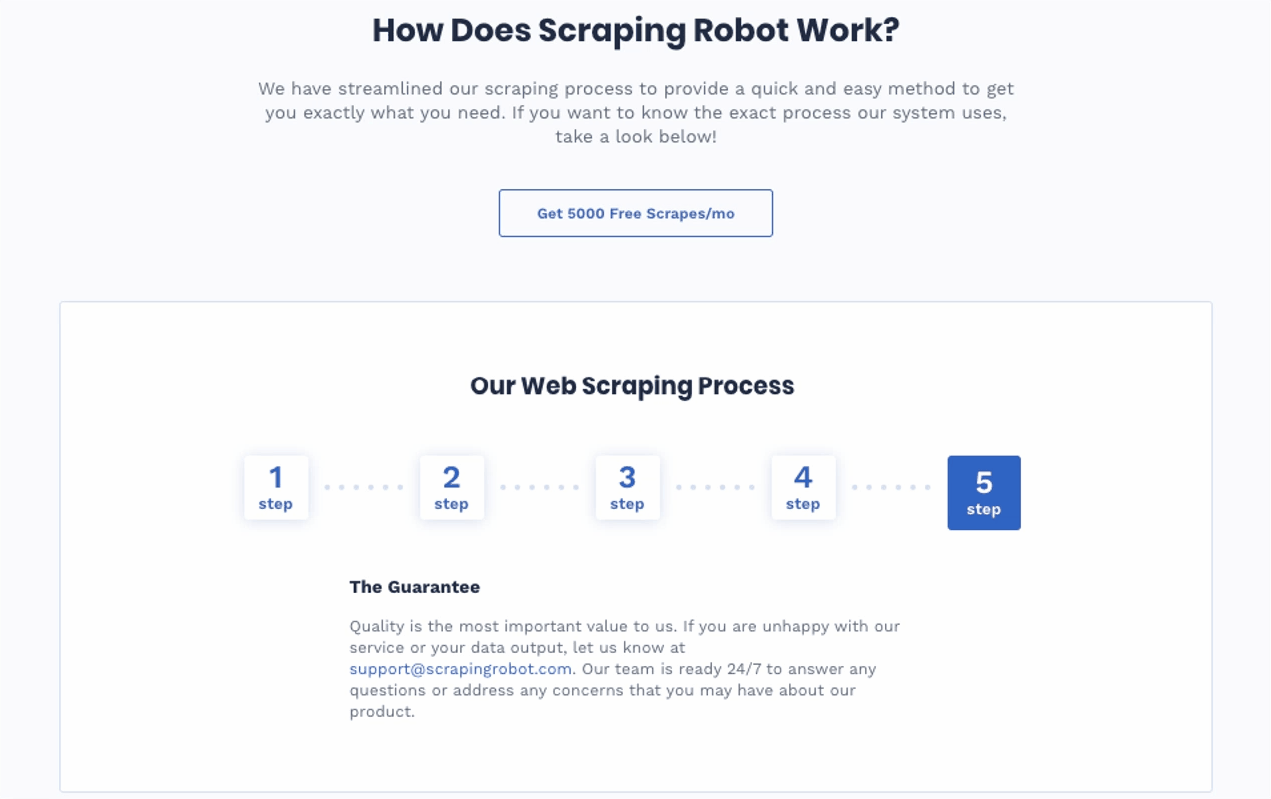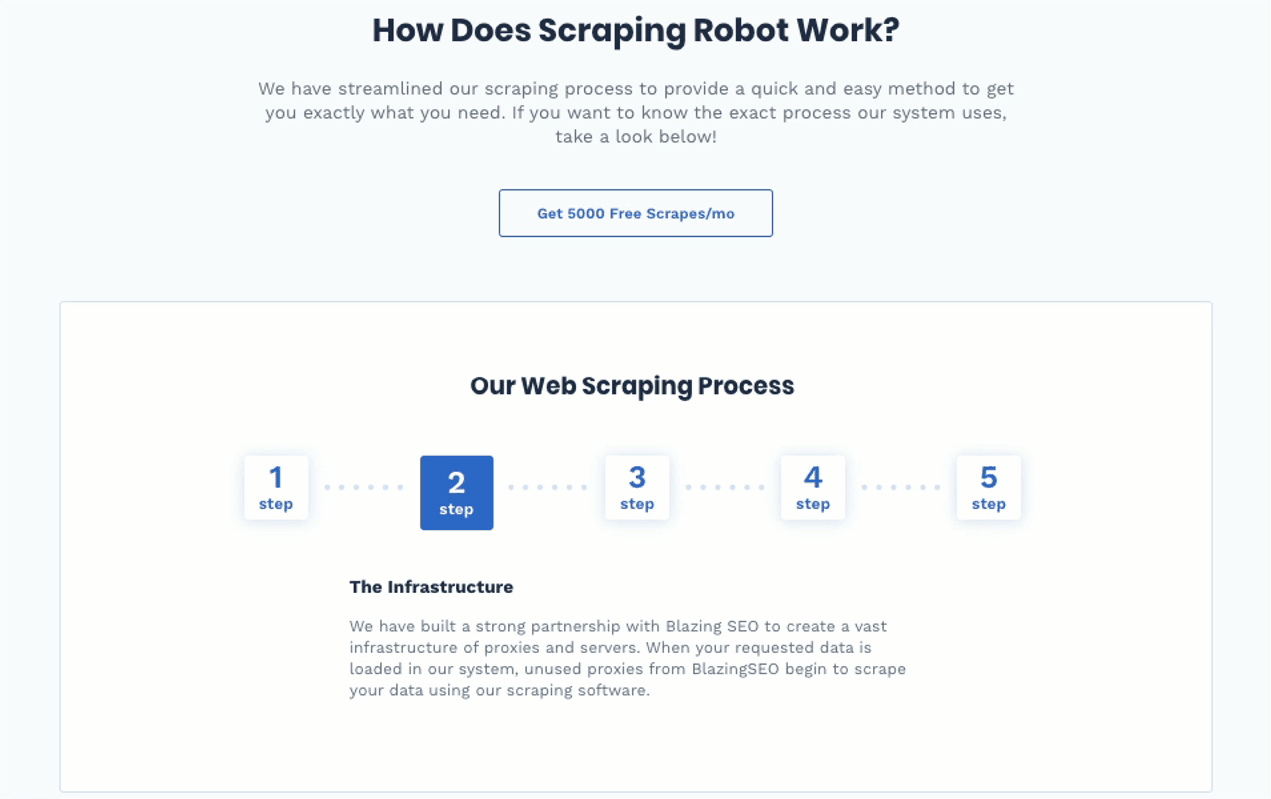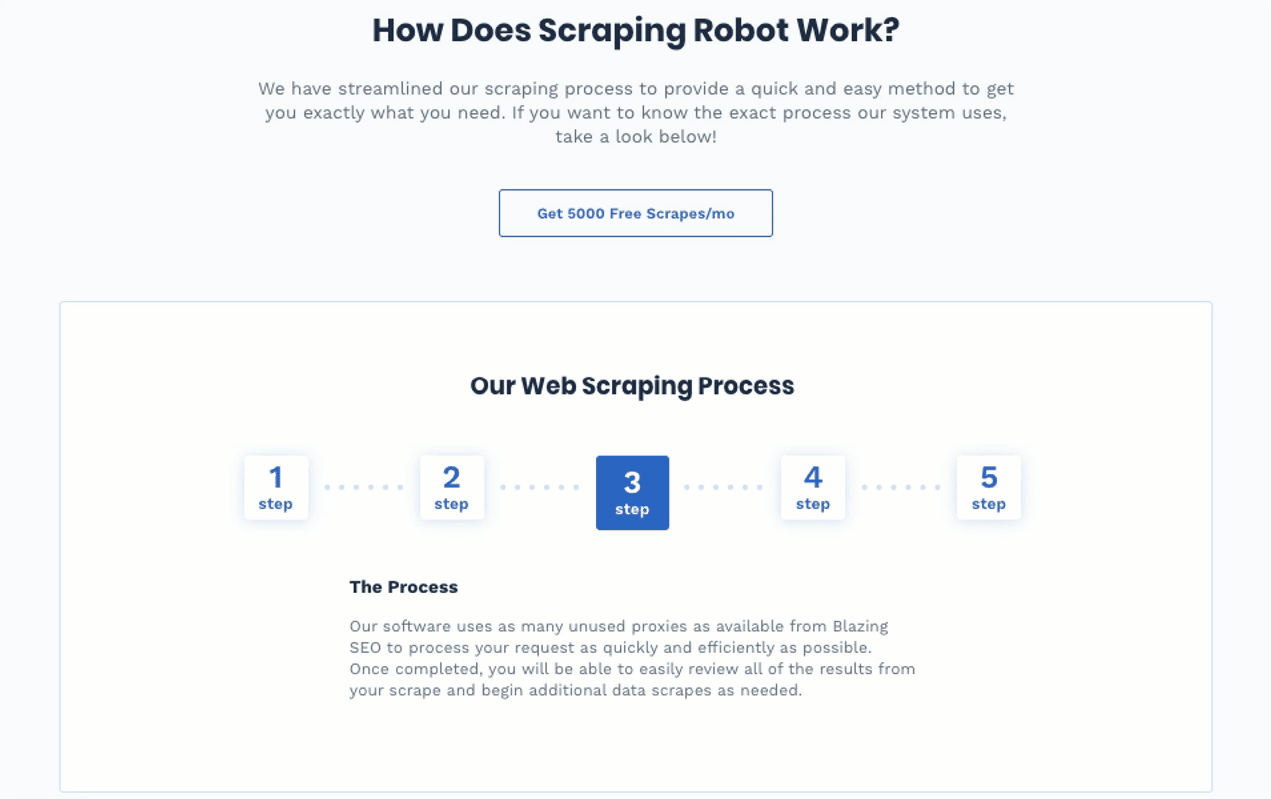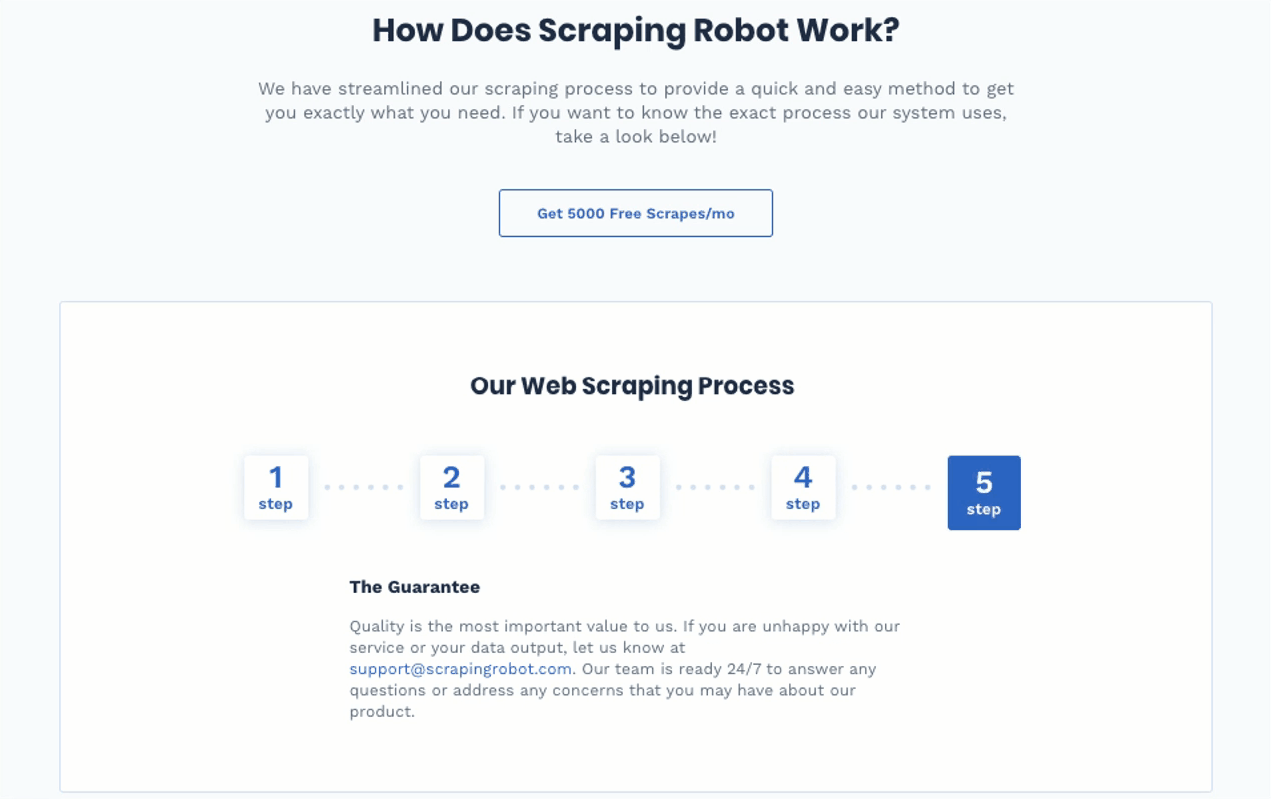
Step #2: Scraping Robot Accesses Blazing SEO
Blazing SEO and Scraping Robot partnered to provide the proxies that handle each scraping request you make. Unused proxies come from Blazing SEO while Scraping Robot’s software handles the scraping.
Step #3: Run Your Scraping Request
Scraping Robot would run your request with as many unused proxies as possible from Blazing SEO. Scraping Robot does this to complete your request in the shortest time possible. The goal here is to complete your request as efficiently and as quickly as possible so you can review your results and initiate new requests.
Step #4: Pay for Your Scraping
The partnership that Scraping Robot established with Blazing SEO makes it possible for them to offer their scraping service at a low cost.
Step #5: Scraping Robot’s Guarantee
Although Scraping Robot offers a “Guarantee” and promises around-the-clock availability to respond to any concerns with their product, it didn’t give any specific guarantees. It’s not clear if you’ll receive a money-back guarantee or not.
Pre-Built Modules
Scraping Robot provides pre-built modules to let you scrape different websites easily and affordably. The scraper has 15 pre-built modules. Let’s explore each of them.
Google Modules
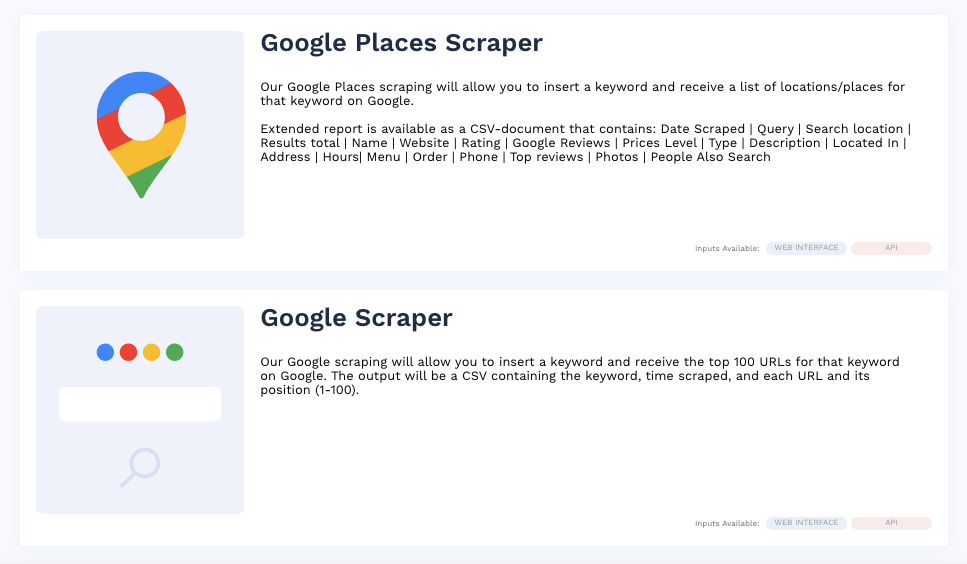
The scraper has two pre-built Google modules:
- Google Places Scraper
- Google Scraper
To use Google Places Scraper, follow these steps
- Name your scraping project
- Enter a keyword and location
For example, I entered the keyword “Calgary rent” in the keyword box.
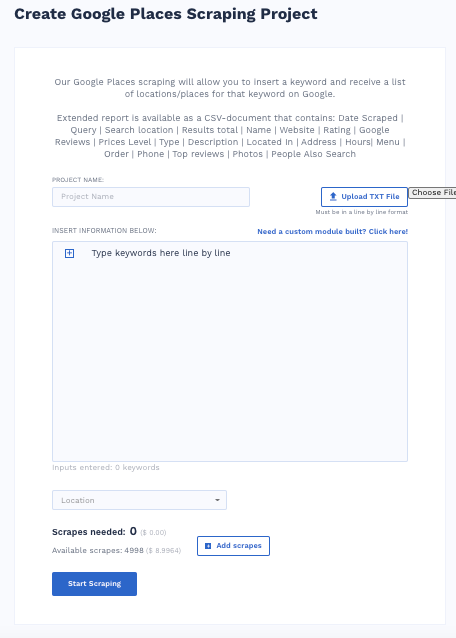
And then, I entered Calgary, Alberta, Canada, in the locations menu. You’ll find the menu just below the keywords box.
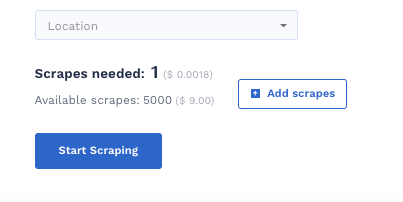
I clicked the blue Start Scraping button to initiate the scraping.
After a few seconds, it turned up my results.
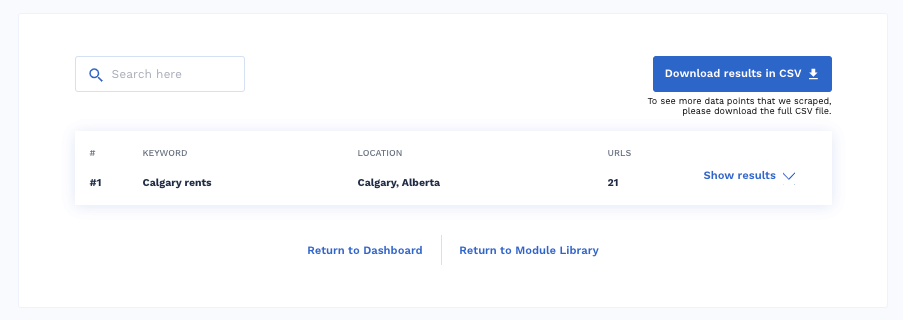
When I click on Show results, I’ll see the full results.
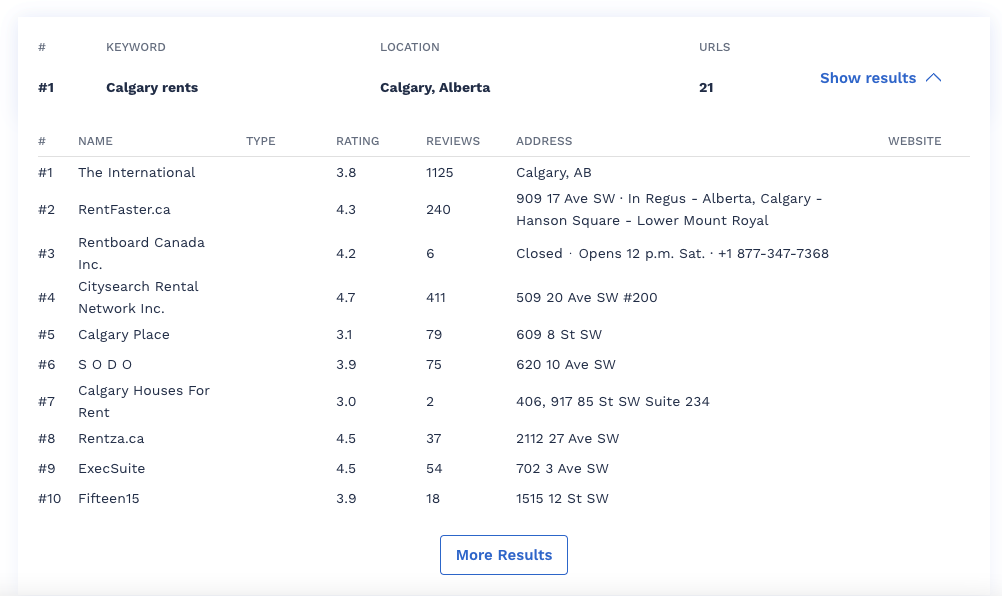
I’d see the remaining results by clicking More Results. When I downloaded the CSV, I got a comprehensive report containing more data than I saw from the dashboard. The extra data include the addresses, closing hours, phone number, number of Google reviews, and ratings.
In total, I got 20 reports of places that rank for that keyword.
For the Google Scraper module, you’d get the top 100 URLs from Google for a specific keyword. The process follows the same steps as Google Places Scraper.
The bad surprise here is that Scraping Robot didn’t list the websites of the places it scraped from Google Place Scraper.
Indeed Modules
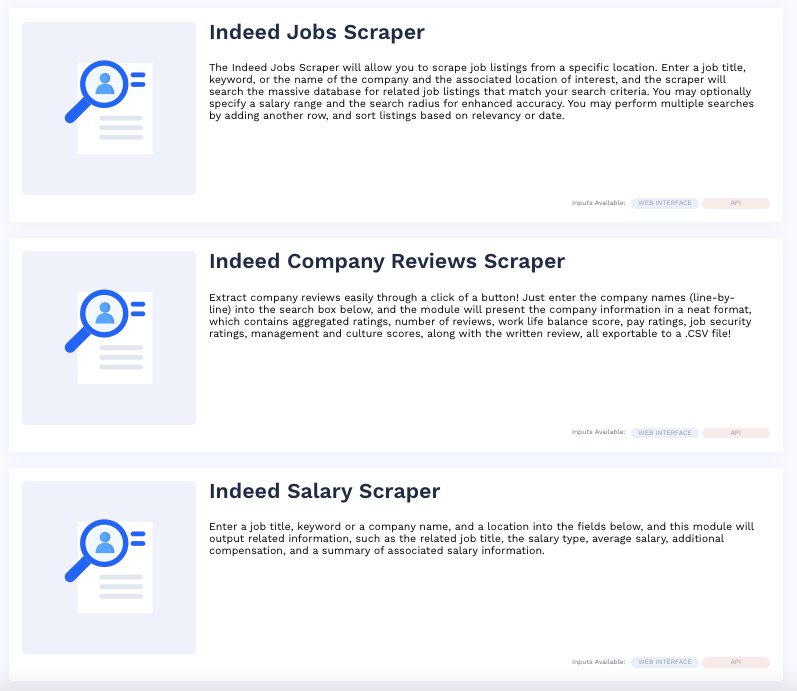

The Indeed module has three submodules.
- Indeed Job Scraper
- Indeed Company Reviews Scraper
- Indeed Salary Scraper
The Job Scraper lets you scrape job listings from a specific location based on a keyword or by the name of the company.
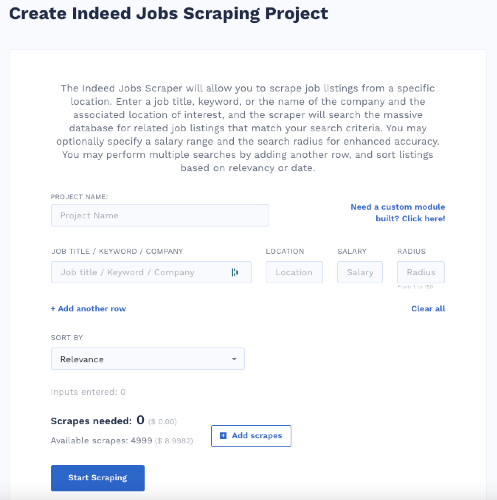
The Company review submodule lets you extract and export company reviews, ratings, and other scores. Name your project and enter the company name to crawl up all the data you want. You can find salary data by filling the form on the salary scraping page.
Amazon Scraper
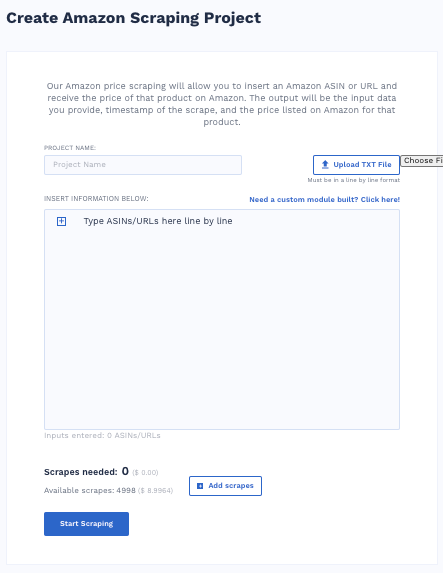
The Amazon scraper module lets you get pricing data by entering an Amazon product’s ASIN or URL and then receive the pricing data of that Amazon product.
HTML Scraper
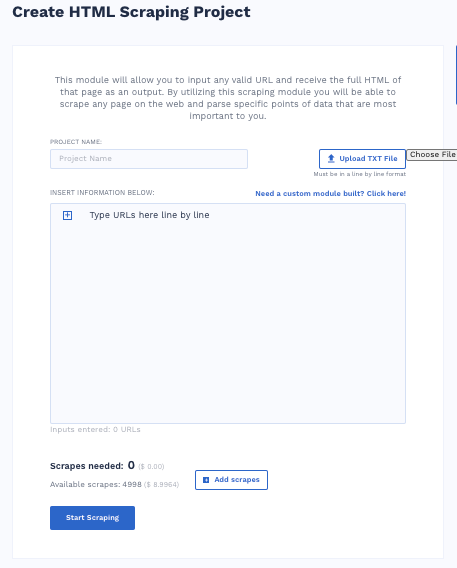
The HTML scraper module lets you grab the full HTML data of any page if you put in the valid URL of the page. This scraper lets you scrape any data you want from the web for storage or to parse it for specific data points that matter to you.
Instagram Scraper
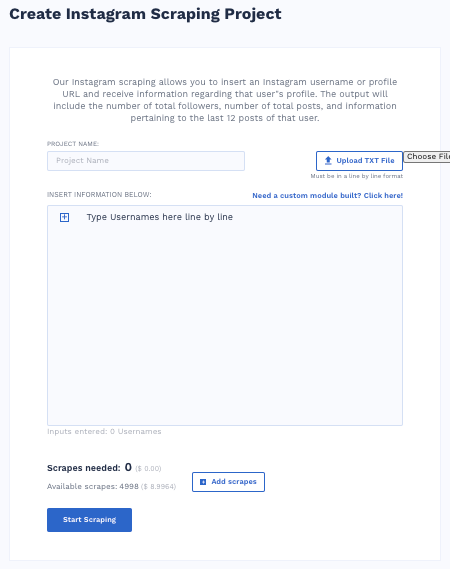
The Instagram scraper module lets you use any Instagram username or the URL of any profile to call up the user’s data. You’ll receive the number of total posts by the users, the user’s total follower count, and detailed information of the last 12 posts.
Facebook Scraper
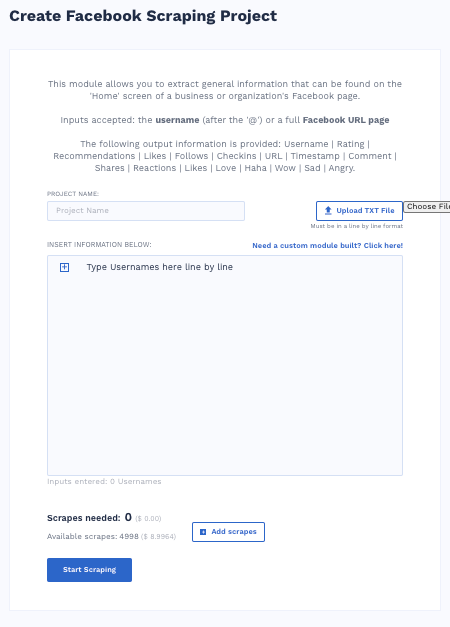
The Facebook scraper module helps you gather publicly available information about an organization based on data from their Facebook page.
You can scrape this data using their username or full Facebook page URL.
Scraping Robot will provide you:
- Username
- Rating
- Recommendations
- Likes
- Follows
- Check-ins
- URL
- Timestamp
- Comment
- Shares
- Reactions
Walmart Product Scraper
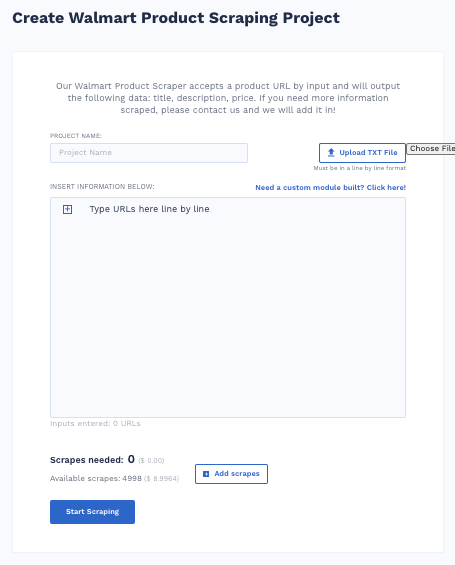
You can use the Walmart Product Scraper to gather data on product descriptions, titles, and prices. Enter a Walmart URL to get the data you want.
Scraping Robot says to contact them if you need to scrape extra data, and they’ll add it.
Aliexpress Product Scraper
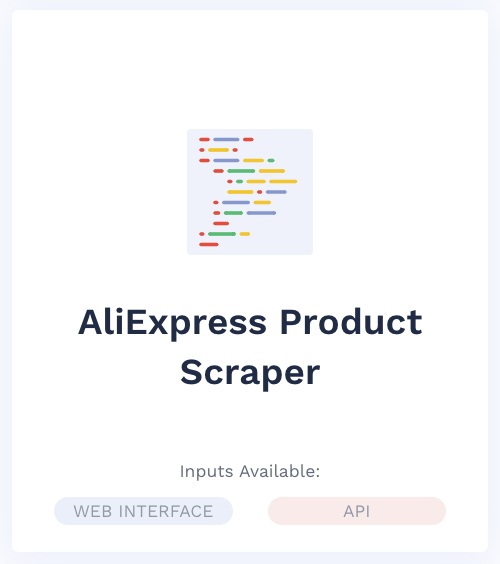
The AliExpress Product Scraper, like the Walmart Module, helps users gather price, title, and description data by inputting a product’s URL. Users can place a custom request to Scraping Robot to scrape more data points.
Home Depot Product Scraper
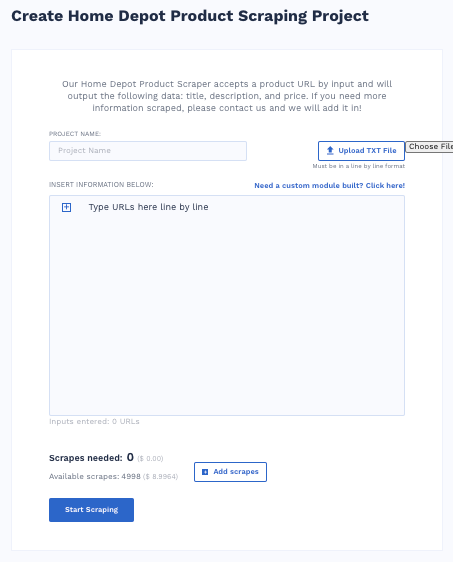
Our Home Depot Product Scraper accepts a product URL by input and will output the following data: title, description, and price. If you need more information scraped, please contact us, and we will add it in!
More Pre-Built Modules
Scraping Robot features a host of pre-built modules that scrape similar data outputs. Each module provides title, price, and description data for users. Others that are not eCommerce focused provide profile data to users.
- eBay Product Scraper
- Wayfair Product Scraper
- Twitter Profile Scraper
- Yellowpages Scraper
- Crunchbase Company Scraper
Custom Module Request
This option is available on request. When clicked, it goes to the Contact Us page. You can contact Scraping Robot to arrange for a custom scraping solution.
Here’s the five-step process for getting custom modules from Scraping Robot.
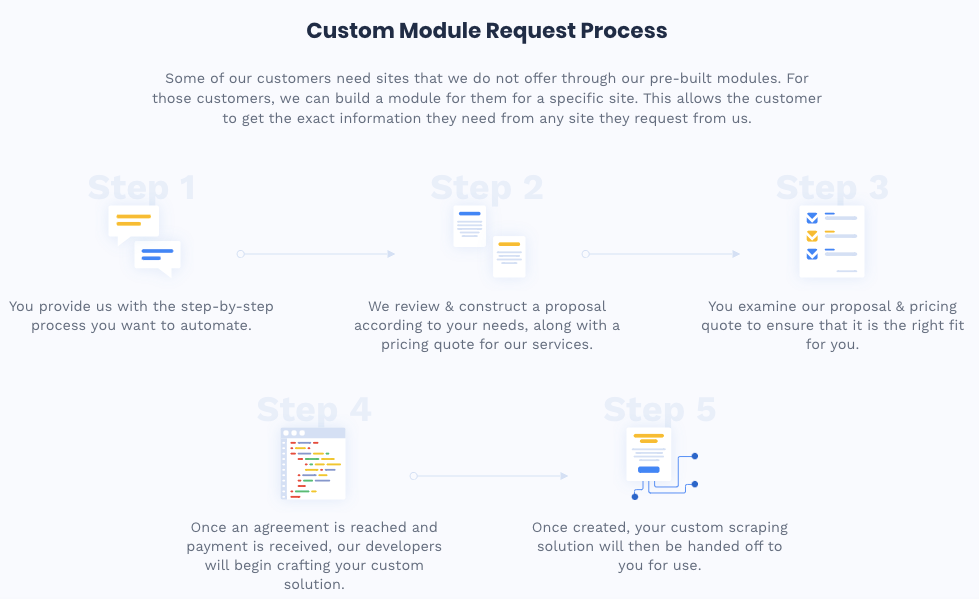
Step #1: Give them the process you want to automate and break it down step-by-step
Step #2: Scraping Robot would develop a proposal based on your request and give you a pricing estimate for the service.
Step #3: You’ll approve or disapprove of the proposal and quote.
Step #4: If you approve of the proposal, you’ll pay and enter an agreement with Scraping Robot.
Step #5: You’ll receive your custom scraping software solution when Scraping Robot completes the development.
More Scraping Robot Features and Functions
Scraping Robot offers more features than just pre-built modules. Let’s explore them.
API
Scraping Robot’s API gives users developer-level access to data at scale. It should reduce the worry and headaches that come with managing servers, proxies, and developer resources.
In your Scraping Robot account, you can find your API Key and an API documentation page. Apart from credit limits, you have no API usage limitations.
Demos Library
The demos library shows you how each module works. So if you’re thinking of seeing how it works, that library is an excellent place to test the software.
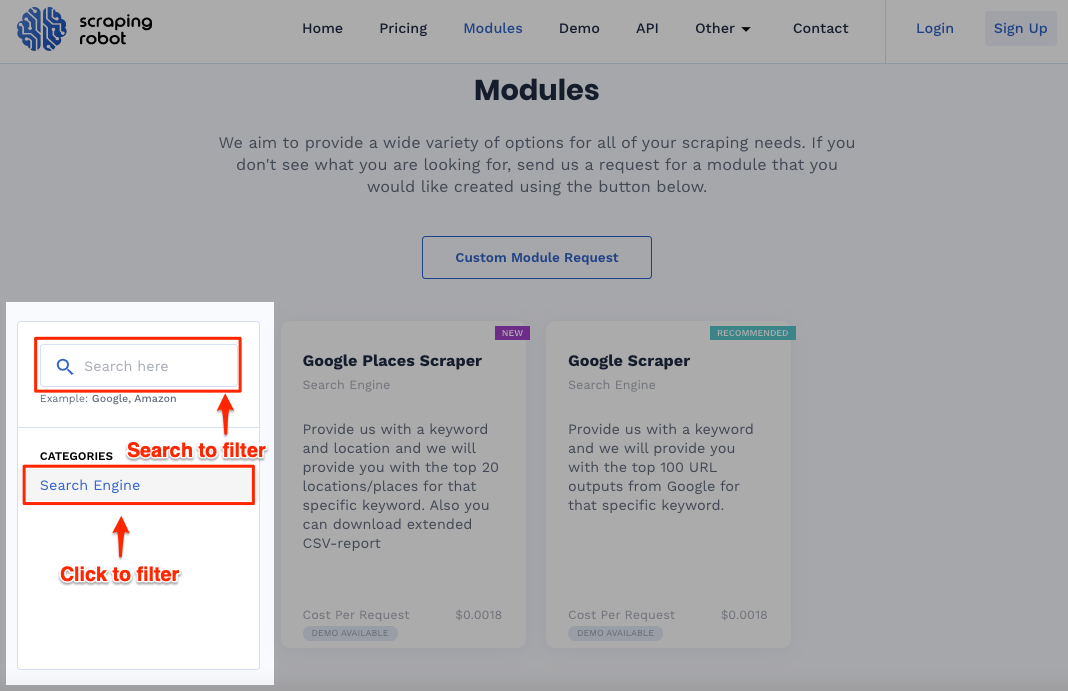
Module Filter
The module filter seems like a feature in development because the click-to-filter function has only the search engine filter at the time of this review. So we can expect profile filters, product filters, and other filters in the future.
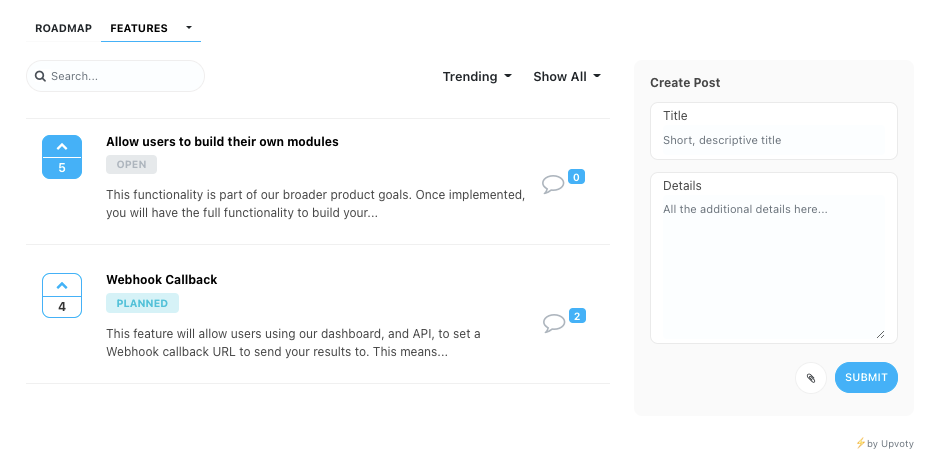
Roadmap
Roadmap lets users see features they Scraping Robot plans to launch in the future or that users have suggested. These features are divided into Planned, In Progress, and Live.

Users can suggest and upvote the features they want to see in Scraping Robot.
Also, on the pricing page, you’ll find that Scraping Robot promises to keep adding new modules.

Pricing
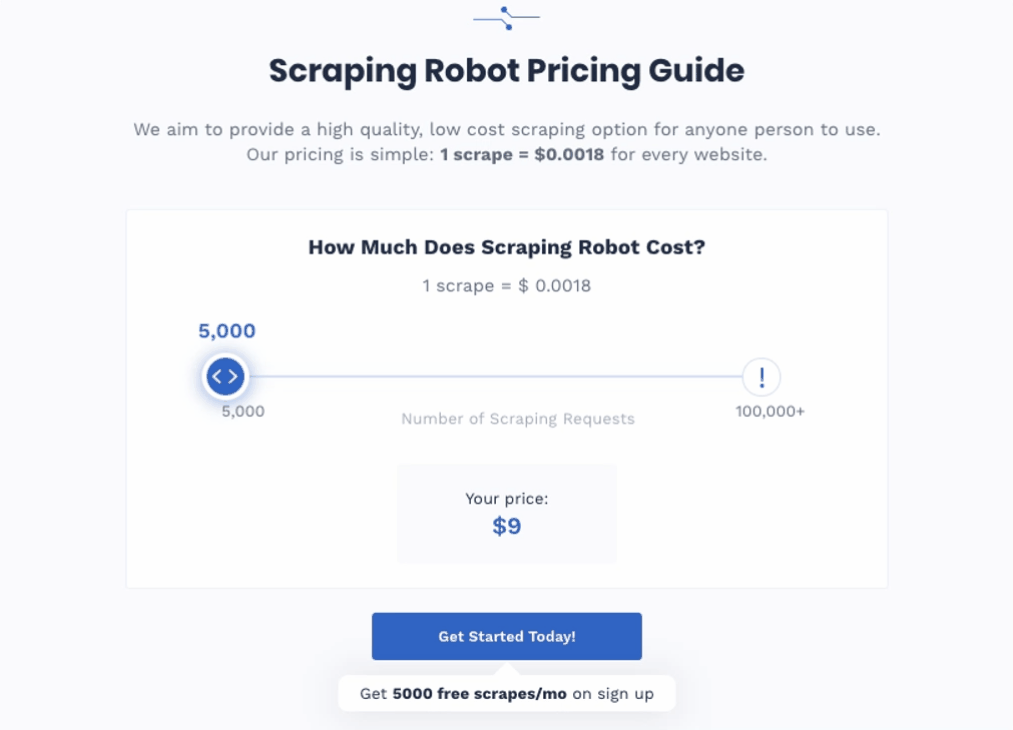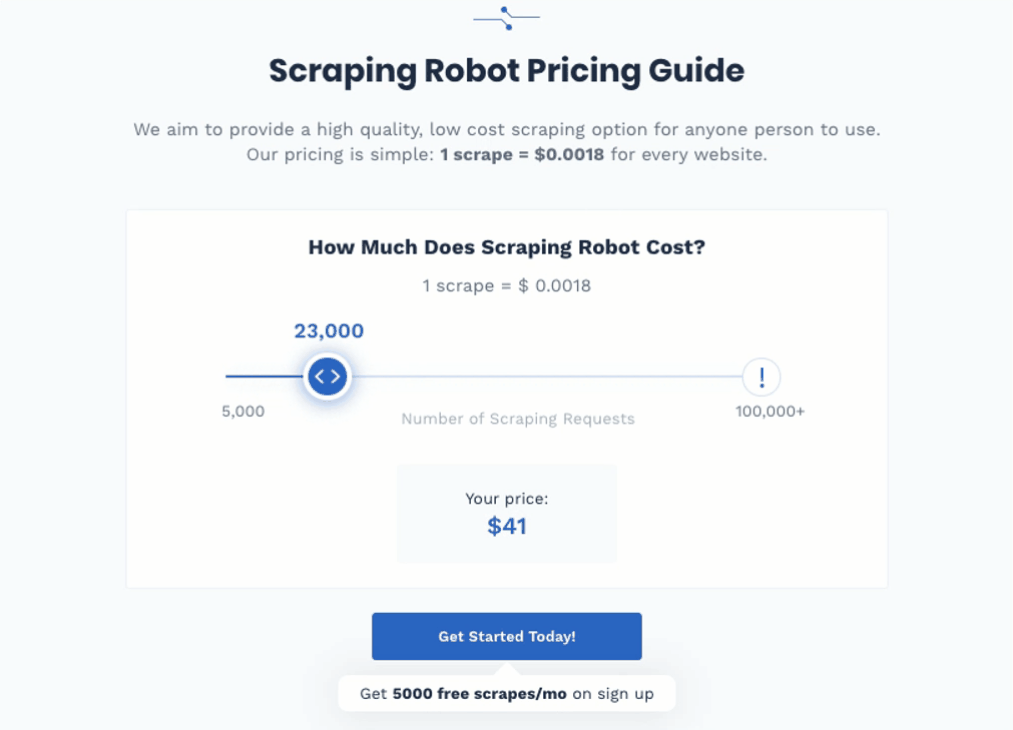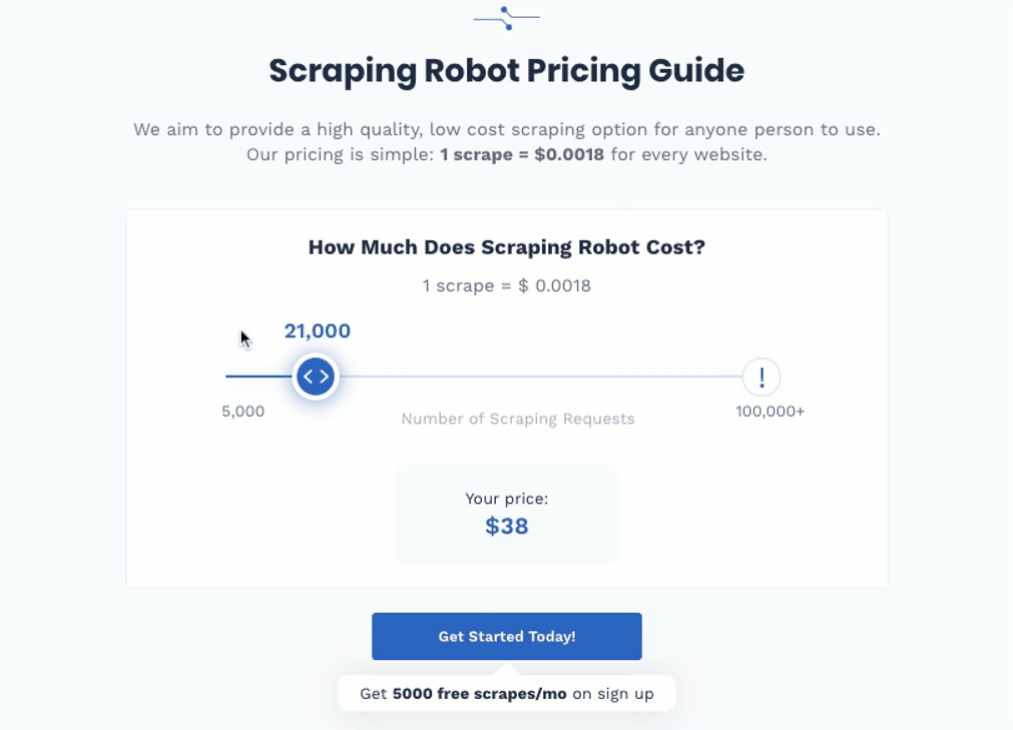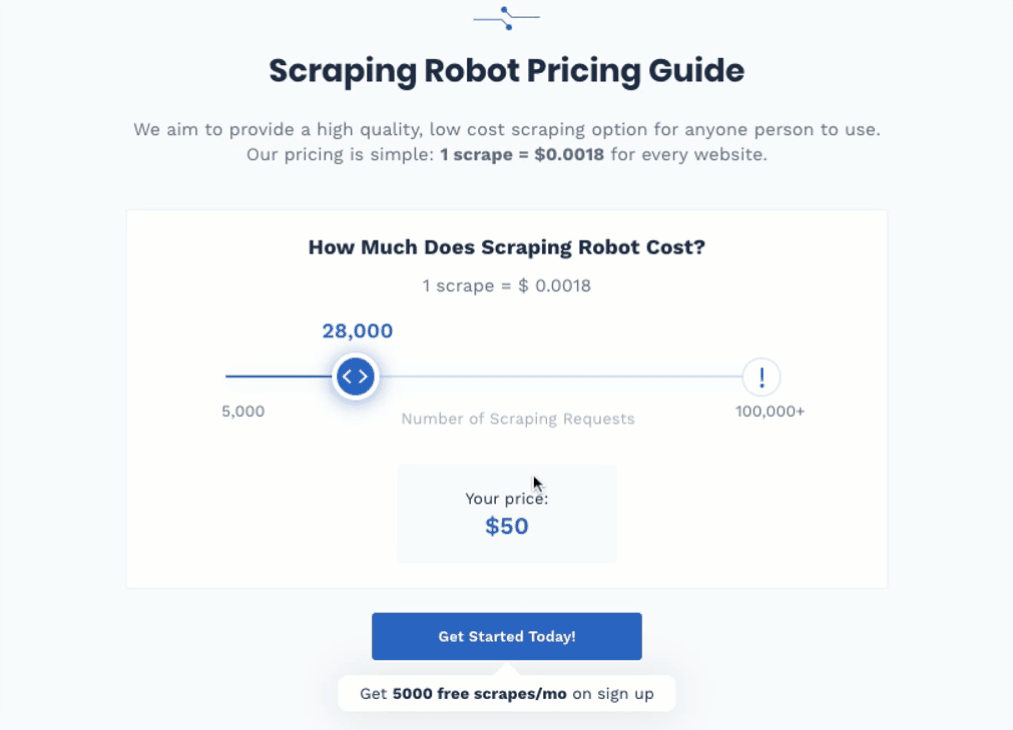
It offers 5,000 free scrapes per month to take care of most people's needs at this level. If you need more scrape, it's only $0.0018 per scrape afterward.
Scraping Robot says they’re able to offer such a low price because of their partnership with premium proxy provider Blazing SEO.
Contact
Although all you’ll see on the Scraping Robots contact page is an email address, you can use their contact form to send your message.
On the corner of most pages, you’ll find the floating Help widget.
Click on this widget to access the form. And then fill the form to send your message.
Happy Scraping — Wrap Up
We generate an awful amount of data daily. IBM estimates it’s 2.5 quintillions of data every day, or in one calculation puts it, 2.5 million Terabytes.
Yes, there’s more than enough data to help you make better business and growth decisions.
If you’re looking to gather data and build intelligence for your organization, Scraping Robot looks like a viable solution without the cost.
The 5,000 free scraping units makes the experience risk free. You start scraping to help you test the business case for using the tool before making any financial commitments to this technology.
Of course, you don’t want to get into legal issues or violate other people. Make sure to apply the most ethical standards in your scraping practice.


Comments 0 Responses